I am very happy to announce v0.3.0 of the padr package, which was introduced in January. As requested by many, you are now able to use intervals of which the unit is different from 1. In earlier version the eight interval values only allowed for a single unit (e.g. year, day, hour). Now you can use any time period that is accepted by seq.Date or seq.POSIXt (e.g. 2 months, 6 hours, 5 minutes) in both thicken and pad. get_interval does test for both the interval and the unit of the interval of the datetime variable from now on.
library(padr)
library(tidyverse)
get_interval(as.Date(c("2017-01-01", "2017-03-01")))
## [1] "2 month"
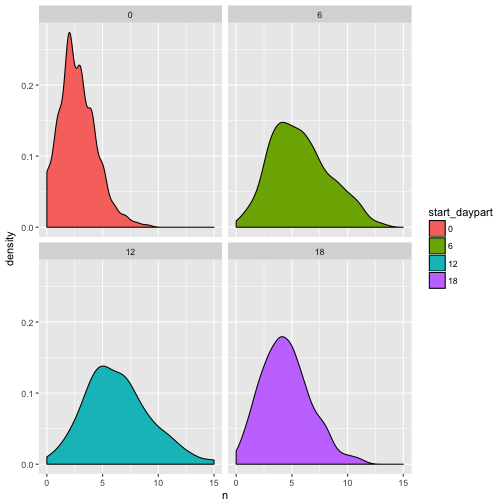
With this new definition of the interval the possibilities of both thicken and pad are expanded. See the following analysis, where the new functionality is demonstrated by aggregating to daypart:
emergency %>%
filter(title == "EMS: CARDIAC EMERGENCY") %>%
thicken(interval = "6 hours", colname = "daypart") %>%
count(daypart) %>%
pad() %>%
fill_by_value(n) %>%
mutate(start_daypart = lubridate::hour(daypart) %>% as.factor()) %>%
ggplot(aes(n)) +
geom_density(aes(fill = start_daypart)) +
facet_wrap(~start_daypart)
## pad applied on the interval: 6 hour
The addition of unit specification to the interval made it unfortunately impossible to make v0.3.0 fully backwords compatible. The two main functions are affected in the the following way.
-
In
thickentheintervalargument now has to be specified. In earlier versions it was optional. When it was not specified, the added variable was one interval level higher than that of the input datetime variable. With the widening of the interval definition, there is not longer a natural step up. -
When the
intervalargument is not specified inpad,get_intervalis applied on the datetime variable. Since this function now returns the units additionally to the interval, padding might now be done at a different interval. In earlier versions, the following dataframe would have 7 rows after padding because the interval ofdtused to be “month”. Nowpadwould return only 4 rows, because the new interval is “2 month”.
example_df <- data.frame(dt = as.Date(c("2017-01-01", "2017-03-01", "2017-07-01")),
y = 1:3)
pad(example_df)
## pad applied on the interval: 2 month
## dt y
## 1 2017-01-01 1
## 2 2017-03-01 2
## 3 2017-05-01 NA
## 4 2017-07-01 3
One should thus be a little more careful that there is no higher unit within the interval that explains the data as well. To reduce the risk of padding at the wrong unit, pad now always prints the interval at which the padding occured.
Reimplementation of pad
The second significant change in this version is the reimplementatiion of pad. Performance was poor when pad was applied on more than a handfull of groups. By leveraging dplyr this is now greatly improved.
Besides, functionality is slightly adjusted as well:
-
When the
intervalargument is not specified and thegroupargument is specified, the interval is now determined on all observations instead of within each group separately. With the new definition of the interval it would far more likely that we get deviating intervals for small groups unintendedly. To prevent this kind of interval overfitting, groups are no longer taking into account when determining the interval. -
For better integration with
dplyr, it is now possible to specifiy the grouping variable(s) forpadwithdplyr::group_by. The following two are interchangeable:
x <- emergency %>% thicken("day", "d") %>% count(title, d)
x %>% pad(group = "title")
x %>% group_by(title) %>% pad()
-
Moreover, both
padandthickennow maintaindplyrgrouping. The grouping of their outputs is equal to the grouping of the input. -
padhas gained thebreak_aboveargument. This is a number in millions. Before starting to pad, the function makes an estimate of the number of returned rows. If the number of rows is above the number specified inbreak_abovethe function will break. This is a safety net for the situation where the interval of the datetime variable is more granualar than the user thinks it is. For instance, when forgetting to applythickenfirst. -
For determining the interval in
padthestart_valand/or theend_valare taken into account, if specified. They are concatenated to the datetime variable before the interval is determined.
Other changes
-
The new function
pad_intpads an integer column, instead of a datetime column. Helpful for datasets where time is specified as just the years, but also for interger id variabels that are incomplete. -
The
fill_used to require specification of all the column names that had to filled. This is annoying when many columns had to be filled. The functions no longer break when no variable names are specified, but instead fill all columns in the data frame. -
In
thickenobservations before thestart_valare now removed from the dataset. They used to be all mapped to thestart_val. The behavior ofthickenis thereby consistent with the behavior ofpad.
Bug fixes
-
When the
end_valis specified inpad, it would mistakenly update thestart_valwith its value. This resulted in the return of only the last line of the padded data.frame, instead of the full padded data.frame. (#13) -
When dt_var has NULL as timezone,
to_posix(helper ofround_thicken, which itself is a helper ofthicken) used to break, and therebythickenitself broke. This is fixed. (#14) -
In
padwith grouping, the function will no longer breaks if for one of the groups thestart_valis behind its last observation, or theend_valis before its first observation. Group is omitted and warning is thrown. If all groups are omitted, function breaks with an informative error. The same goes of course when there is no grouping. (#24) -
Both
padandthickennow throw informative errors when the start_val or end_val (padonly) are of the wrong class.